
Создание безопасного программного
В их работе рассматривалась синхронная сеть связи из n участников, где каналы связи небезопасны и стороны, также как и противник, ограниченны в сво-их действиях вероятностным полиномиальным временем. В своей модели вычислений они показали, что в предположении существования односто-ронних функций с секретом можно построить многосторонний протокол (с n участниками) конфиденциальных вычислений любой функции в присут-ствие пассивных противников (т.е., противников, которым позволено толь-ко "прослушивать" коммуникации). Для некоторых типов противников (для византийских сбоев) авторы привели протокол для конфиденциально-го вычисления любой функции, где ( n/2 -1) участников протокола явля-ются нечестными (или ( n/2 -1)-протокол конфиденциальных вычислений).
В дальнейшем изучались многосторонние протоколы конфиденциаль-ных вычислений в модели с защищенными каналами. Было показано, что если противник пассивный, то существует ( n/2 -1)-протокол для конфиденциального вычисления любой функции. Если противник активный (т.е., противник, которому позволено вмешиваться в процесс вычислений), тогда любая функция может быть вычислена посредством ( n/3 -1)-протокола конфиденциальных вычислений. Эти протоколы являются безопасными в присутствие неадаптивных противников (т.е., противников, действующих в схеме вычислений, в которой множество участников независимо, но фиксировано).
В последнее время исследуются вычисления для случая активных противников, ограниченных в работе вероятностным полиномиальным временем, где часть участников вычислений может быть "подкуплена" противником и многосторонние конфиденциальные вычисления при наличии незащищенных каналов и с вычислительно неограниченным против-ником, а также исследовались многосторонние конфиденциальные вычисления с нечестным большинством участников при наличии защищенных каналов. Кроме того, изучаются многосторонние протоколы конфиденциальных вычислений при наличии защищенных каналов и динамического противника (т.е., противника, который может "подкупать" различных участников в разные моменты времени).
В фундаментальной работе предложены определения для многосторонних конфиденциальных вычис-лений при наличии защищенных каналов и в присутствии адаптивных про-тивников.
В работе , авторы начали комплексные исследования асинхронных конфиденциальных вычислений. Они рассмотрели полностью асинхрон-ную сеть (т.е., сеть, где не существует глобальных системных часов), в ко-торой стороны соединены защищенными каналами связи. Автор привел первый асинхронный протокол византийских соглашений с оптимальной устойчивостью, где противник может "подкупать" n/3 -1 из n участников вычислений.
Определение односторонней функции, описание используемых примитивов, схем и протоколов
В качестве одного из основных математических объектов в данной работе используются односторонние функции, то есть вычислимые функции, для которых не существует эффективных алгоритмов инвертирова-ния. Необходимо отметить, что односторонняя функция - гипотетический объект, поэтому называть конкретные функции односторонними матема-тически некорректно. Впервые такую гипотетическую конструкцию для конкретного криптографического приложения, - открытого распределения ключей, предложили У. Диффи и М. Хеллман в 1976 г. (см, например, оп-ределения в работе ). Они показали, что вычисление степеней в мульти-пликативной группе вычетов над конечным полем является простой зада-чей с точки зрения состава необходимых вычислений, в то время как из-влечение дискретных логарифмов над этим полем - предположительно сложная вычислительная задача.
Неформально говоря, для двух независимых множеств X и Y функция f:X- > Y называется односторонней, если для каждого x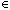 Y вычислительно трудно по-лучить такой x
Y вычислительно трудно по-лучить такой x
Далее приводится формальное определение односторонней функции в терминах теории сложности вычислений. Для этого введем следующее обозначение. Пусть a
Функция f называется односторонней, если существует полиномиальная машина Тьюринга T, которая на любом входе x 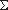 вычисляет f(x) и для любого полиномиального алгоритма A справедливо следующее.
вычисляет f(x) и для любого полиномиального алгоритма A справедливо следующее.
Пусть x n и слово y=f(x) подано на вход алгоритма A. Тогда для любого полинома p и для всех достаточно больших n вероятность Prob(f(A(y))=y)).
Вероятность берется по выбору значения x из
(n,t)-Пороговые схемы. Используемая в данном разделе (n,t)-пороговая схема, известная как схема разделения секрета Шамира, - это протокол между n+1 участниками, в котором один из участников, именуемый дилер - Д, распределяет частичную информацию (доли) о секрете между n участниками так, что:
-
любая группа из менее чем t участников не может получить любую информацию о секрете;
любая группа из не менее чем t участников может вычислить сек-рет за полиномиальное время.
Пусть секрет s - элемент поля F. Чтобы распределить s среди участни-ков P1,...,Pn, (где n< |F| ) дилер выбирает полином f F\{0} - общедоступная информация для Pi (xi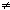 j).
j).
Вследствие того, что существует один и только один полином степени не менее k-1, удовлетворяющий f(xi)=si для k значений i, схема Шамира удовлетворяет определению (n,t)-пороговых схем. Любые t участников могут найти значение f по формуле:
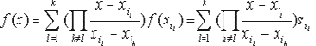
Следовательно
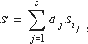
где a1,...,ak получаются из
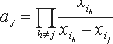
Таким образом, каждый ai является ненулевым и может быть легко вычислен из общедоступной информации. Проверяемая схема разделения секрета. Пусть имеется n участников вычислений и t* (значение t* не более порогового значения t) из них могут отклоняться от предписанных протоколом действий. Один из участников назначается дилером Д, которому (и только ему) становится известен секрет (секретная информация) s. На первом этапе дилер вне зависимости от действий нечестных участников осуществляет привязку к уникальному параметру u.
Идентификатор дилера известен всем абонентам системы. На втором этапе осуществляется открытие (восстановление) секрета s всеми честными участниками системы. И если дилер Д - честный, то s=u.
Проверяемая схема разделения секрета ПРС представляет собой пару многосторонних протоколов (РзПр,ВсПр), - а именно протокола разделения секрета и проверки правильности разделения РзПр и протокола восстановления и проверки правильности восстановления секрета ВсПр, при реализации которых выполняются следующие условия безопасности. Условие полноты. Для любого s, любой константы c>0 и для достаточно больших n вероятность Prob((n,t,t*)РзПр=(Да,s) t* < t & Д - честный)>1-n-c.
Условие верифицируемости. Для всех возможных эффективных алгоритмов Прот, любой константы c>0 и для достаточно больших n вероятность
Prob((t*,(Да,u))ВсПр=(s=u)| (n,t,t*)РзПр=(Да,u)& t* < t & Д - честный)n-c.
Условие неразличимости. Для секрета s*
Prob(s*=s |(n,t,t*)РзПр=(Да,s*) & Д - честный)< 1/ |S| .
Свойство полноты означает, что если дилер Д честный и количество нечестных абонентов не больше t, тогда при любом выполнении протокола РзПр завершится корректно с вероятностью близкой к 1. Свойство верифицируемости означает, что все честные абоненты выдают в конце протокола ВсПр значение u, а если Д - честный, тогда все честные абоненты восстановят секрет s=u. Свойство неразличимости говорит о том, что при произвольном выполнении протокола РзПр со случайно выбранным секретом s*, любой алгоритм Прот не может найти s*=s лучше, чем простым угадыванием.
Широковещательный примитив (Br-субпротокол). Введем следующее определение. Протокол называется t-устойчивым широковещательным протоколом, если он инициализирован специальным участником (дилером Д), имеющим вход m (сообщение, предназначенное для распространения) и для каждого входа и коалиции нечестных участников (числом не более t) выполняются условия.
Условие завершения. Если дилер Д - честный, то все честные участники обязательно завершат протокол.
Кроме того, если любой честный участник завершит протокол, то все честные участники обязательно завершат протокол.
Условие корректности. Если честные участники завершат протокол, то они сделают это с общим выходом m*. Кроме того, если дилер честный, тогда m*=m.
Необходимо подчеркнуть, что свойство завершения является более слабым, чем свойство завершения в византийских соглашений. Для Br-протокола не требуется, чтобы несбоящие процессоры завершали протокол, в том случае, если дилер нечестен.
Br-протокол
Код для дилера (по входу m):
Код для процессоров:
Предложение 2.1. Br-протокол является t-усточивым широковещательным протоколом для противников, которые могут приостанавливать отправку сообщений.
Доказательство. Если дилер честен, то все несбоящие процессоры получают сообщение (сбщ,m) и, таким образом, завершают протокол с выходом m. Если несбоящий процессор завершил протокол с выходом m, то он посылает сообщение (эхо,m) ко всем другим процессорам и, таким образом, каждый несбоящий процессор завершит протокол с выходом m. Ниже описывается  BB. В протоколе принимается, что идентификатор дилера содержится в параметре m.
BB. В протоколе принимается, что идентификатор дилера содержится в параметре m.
Протокол BB
Код для дилера (по входу m):
Код для процессора Pi:
Протокол византийского соглашения (BA-субпротокол). Введем следующее определение. При византийских соглашениях для любого начального входа xi, i
Условие завершения. Все честные участники вычислений в конце протокола принимают значение d.
Условие корректности. Если существует значение x такое, что для честных участников xi=x, тогда d=x.
Обобщенные модели вычислений для сети синхронно и асинхронно взаимодействующих процессоров
Принимаемая модель создания программного обеспечения на базе методов конфиденциального вычисления функции позволяет единообразно трактовать как ошибки, возникающие, например, в результате сбоев технических средств, так и ошибки, возникающие за счет привнесения в вычислительный процесс преднамеренных программных дефектов. Следует отметить, что протоколы конфиденциального вычисления функции относятся к протоколам, которые предназначены, прежде всего, для защиты процесса вычислений от действия "разумного" злоумышленника, то есть от злоумышленника, который всегда выбирает наихудшую для нас стратегию.
В модели вводится дополнительный параметр t, t < n, - максимальное число участников, которые могут отклоняться от предписанных протоколом действий, то есть максимальное число злоумышленников. Поскольку злоумышленники могут действовать заодно, обычно предполагается, что против протокола действует один злоумышленник, который может захва-тить и контролировать любые t из n процессоров по своему выбору.
Модель сбоев и модель противника
Рассматривается сеть взаимодействующих процессоров. Некоторые процессоры могут "сбоить". При сбоях, приводящих к останову (FS-сбоях), сбоящий процессор может приостановить в некоторый момент времени отправку своих сообщений. В то же время предполагается, что сбоящие процессоры продолжают получение сообщений и могут выдавать "некую информацию" в свои выходные каналы. При Византийских сбоях (By-сбоях) процессоры могут произвольным образом сотрудничать друг с другом с целью получения необходимой для них информации или с целью нарушения процесса вычислений.
При By-сбоях сбоящие процессоры могут объединять свои входы и изменять их. В то же время это должно происходить при условии невозможности изучения любой информации о входах несбоящих процессоров.
Сбои могут быть статическими и динамическими. При статических сбоях множество сбоящих процессоров фиксировано в начале и процессе вычислений, при динамических - множество сбоящих процессоров может меняться, как может меняться и характер самих сбоев. Сбоящие процессоры будут также называться нечестными участниками вычислений, в противоположность честным участникам, которые выполняют предписанные вычисления.
Противника можно представлять как некий универсальный процессор, действия которого заключаются в стремлении "сделать" процессоры сети сбоящими ("подкупить" их).
По аналогии со сбоями противник может быть динамическим и статическим. Статическим противником является противник, который "сотрудничает" с фиксированным количеством сбоящих процессоров ("подкупленных" противником). При действиях динамического противника количество сбоящих процессоров может меняться (в том числе непредсказуемым образом).
Кроме того, противник может быть активным и пассивным, а также с априорными и апостериорными протокольными и раундовыми действиями. Пассивный противник не может изменять сообщения, циркулируемые в сети. Активный противник может знать все о внутренней конфигурации сети, может читать и изменять все сообщения сбоящих процессоров и может выбирать сообщения, которые будут посылать сбоящие процессоры при вычислениях. Активный динамический противник может в начале каждого раунда "подкупить" несколько новых процессоров. Таким образом, он может изучить информацию, получаемую ими в текущем раунде, и принять решение "подкупить" ли ему новый процессор, или нет. Такой противник может собирать и изменять все сообщения от сбоящих процессоров к несбоящим. В то же время гарантируется, что все сообщения (в том числе, между честными процессорами) будут доставлены адресатам в конце текущего раунда.
Действия аналогичного характера активный противник может выполнить не только в течение раунда (в его начале и конце), но и до начала выполнения протокола и после его завершения.
Противник называется t-противником, если он сотрудничает с t процессорами.
Модель взаимодействия
Взаимодействие процессоров может осуществляться посредством конфиденциальных и открытых каналов связи. Каждые два процессора могут быть иметь симплексное, полудуплексное или дуплексное соединение. При этом каждое из соединений, в зависимости от решаемой задачи, в некоторый промежуток времени, может быть либо конфиденциальным, либо открытым. Кроме того, может существовать широковещательный канал связи, то есть канал, посредством которого один из процессоров может одновременно распространить свое сообщение всем другим процессорам вычисли-тельной системы. Такой канал еще называется каналом с общей шиной.
Взаимодействие в сети характеризуется трафиком T, который может представлять собой совокупность сообщений, полученных участниками вычислений в r-том раунде в установленной модели взаимодействия.
Синхронная модель вычислений
Рассматривается сеть процессоров, функционирование которой синхронизируется общими часами (синхронизатором). Каждое локальное (внутреннее) вычисление соответствует одному моменту времени (одному такту часов). В данной модели отрезок времени между i и i+1 тактами называется раундом при синхронных вычислениях. За один раунд протокола каждый процессор может получать сообщения от любого другого процессора, выполнять локальные (внутренние) вычисления и посылать сообщения всем другим процессорам сети. Имеется входная лента "только-для-чтения", которая первоначально содержит строку ? (k) (например вида 1k), при этом k является параметром безопасности системы. Каждый процессор имеет ленту случайных значений, конфиденциальную рабочую ленту "только-для-чтения" (первоначально содержащую строку ?), конфиденциальную входную ленту "только-для-чтения" (первоначально содержащую строку xi), конфиденциальную выходную ленту "только-для-записи" (первоначально содержащую строку ?) и несколько коммуникационных лент.
Между каждой парой процессоров i и j существует конфиденциальный канал связи, посредством которого i посылает безопасным способом сообщение процессору j. Данный канал (коммуникационная лента) исключает запись для i и исключает чтение для j. Каждый процессор i имеет также широковещательный канал, представляющий собой ленту, исключающую запись для i и являющийся каналом "только-для-чтения" для всех остальных процессоров сети.
Предполагается, что в раунде r для каждого процессора i существует однозначно определенное сообщение (возможно пустое), которое распространяет процессор i в этом раунде и для каждой пары процессоров i и j существует единственное сообщение, которое i может безопасным образом послать j в данном раунде. Все каналы являются помеченными так, что каждый получатель сообщения может идентифицировать его отправителя.
Процессор i запускает программу ?i, совокупность которых, реализует распределенный алгоритм П. Протоколом работы сети называется n-элементный кортеж P=( ?1, ?2,.., ?n). Протокол называется t-устойчивым, если t процессоров являются сбоящими во время выполнения протокола. Историей процессора i являются: содержание его конфиденциального и общего входа, все распространяемые им сообщения, все сообщения, полученные i по конфиденциальным каналам связи, и все случайные параметрами, сгенерированные процессором i во время работы сети.
Идеальный и реальный сценарии
Для доказуемо конфиденциального вычисления вводятся понятия идеального и реального сценария . В идеальном сценарии дополнительно вводится достоверный процессор (TP-процессор). Процессоры конфиденциально посылают свои входы ТР-процессору, который вычисляет необходимый результат (выход) и также конфиденциально посылает его обратно процессорам сети. Противник может манипулировать с этим результатом (вычислить или изменить его) следующим образом. До начала вычислений он может подкупить один из процессоров и изучить его секретный вход. Основываясь на этой информации, противник может подкупить второй процессор и изучить его секретный вход.
Это продолжается до тех пор пока противник не получит всю необходимую для него информацию. Далее у противника есть два основных пути. Он может изменить входы нечестных процессоров. После чего те, вместе с корректными входами честных процессоров, направляют свои новые измененные входы ТР-процессору. По получению от последнего выходов (значения вычисленной функции) противник может приступить к изучению выхода каждого нече-стного процессора. Второй путь заключается в последовательном изучении входов и выходов процессоров, подключая их всякий раз к числу нечестных. В данном случае рассматривается противник, который не только может изучать входы нечестных процессоров, но и менять их, изучать по полученному значению функции входы честных процессоров.
В реальном сценарии не существует ТР-процессора, и все участники вычислений моделируют его поведение посредством выполнения многостороннего интерактивного протокола.
Грубо говоря, считается, что вычисления в действительности (в реальном сценарии) безопасны, если эти вычисления "эквивалентны" вычислениям в идеальном сценарии. Точное определение (формальное определение) понятия эквивалентности в этом контексте является одной из основных проблем в теории конфиденциальных вычислений.
Асинхронная модель вычислений
В данном подразделе рассматривается полностью асинхронная сеть из n процессоров, которые соединены открытыми или конфиденциальными каналами. При этом не существует единых глобальных часов. Любое сообщение в сети может быть задержано независимым образом. В то же время считается, что каждое посланное сообщение обязательно будет получено адресатом. Вопрос о переупорядочивании сообщений не исследуется.
Вычисления в асинхронной модели рассматривается как последовательность шагов. На каждом шаге активизируется один из процессоров. При этом активизация процессора происходит по получении им сообщения. После чего он выполняет внутренние вычисления и возможно выдает сообщения в свои выходные каналы. Порядок шагов определяется Планировщиком (D), неограниченным в вычислительной мощности.
Каналы, являющиеся конфиденциальными или открытыми, рассматриваются как частные планировщики (PDj). Информация, известная частному планировщику, есть не что иное как сообщения, посланные от источника сообщений их адресату. В данной модели вычислений каждый их шах рассматривается как раунд при асинхронных вычислениях. Идеальный и реальный сценарии в асинхронной модели
Сценарий в асинхронной модели с ТР-участником заключается в добавлении ТР-процессора в существующую асинхронную сеть при наличии t потенциальных сбоев (сбоящих процессоров). При этом честные процессоры, также как и ТР-процессор не могут ожидать наличия более, чем n-t входов для вычислений с целью получения их выхода, так как t процессоров (сбоящие процессоры) могут никогда не присоединиться к вычислениям.
Асинхронный ТР-сценарий
В начале вычислений процессоры посылают свои входы ТР-процессору. В то же время, существует планировщик D, который доставляет сообщения участников некоторому базовому подмножеству процессоров, мощностью не меньше n-t, обозначаемому как C и являющемуся независимым от входов честных процессоров. ТР-процессор по получению входов - аргументов функции (возможно некорректных) из множества C, предопределенно оценивает значение вычисляемой функции, основываясь на C и входах участников из С. (Здесь для корректности может использоваться следующее предопределенное оценивание: установить входы из C в 0 и вычислить данную функцию). Затем ТР-процессор посылает значение оценочной функции обратно участникам совместно с базовым множеством С. Наконец честные процессоры вычислений выдают то, что они получили от ТР-участника. Нечестные участники выдают значение некоторой независимой функции, информацию о которой они "собирали" в процессе вычислений. Эта информация может состоять из их собственных входов, слу-чайных значений, используемых при вычислениях и значения оценочной функции.
Так же как и в синхронной модели, вычисления в реальной асинхронной модели безопасны, если эти вычисления "эквивалентны" вычислениям в ТР-сценарии.
Далее в соответствии с работой сделаем попытку формализовать понятия полноты и безопасности протокола асинхронных конфиденциальных вычислений.
Безопасность асинхронных вычислений
Для удобства мы унифицируем коалицию нечестных процессоров и планировщика. Это не увеличит мощность противника в ТР-сценарии, так как и нечестные участники, и планировщик имеют неограниченную вычислительную мощность.
Для вектора 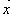
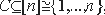 , пусть , спроектированный на индексы из C. Для подмножества B
, пусть , спроектированный на индексы из C. Для подмножества B 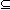
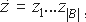 , пусть
, пусть 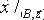 подстановкой входов из B соответствующими входами из
подстановкой входов из B соответствующими входами из 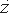 [n] как
[n] как 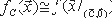
Пусть A - область возможных входов процессоров и пусть R - область случайных входов. ТР-противник это кортеж А=(B,h,c,O), где B [n] | |C| 
Функции h и O представляют собой программы нечестных процессо-ров, а функция c - комбинацию планировщика и программ нечестных участников вычислений.
Пусть f:An - > A для некоторой области A. Выход функции вычисления f в ТР-сценарии по входу А=(B,h,c,O) - это n-vector ?(A) = ?1(A)...?n(A) случайных переменных, удовлетворяющих для каждого 1  n:
n:
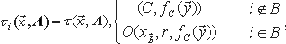
где r объединенный случайный вход нечестных процессоров, C= (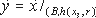
Акцентируем внимание на то, что выход сбоящих процессоров и вы-ход несбоящих процессоров вычисляется на одном и том же значении слу-чайного входа r.
Далее формализуем понятие вычисления "в реальной жизни".
 , с планировщиком D и коалиции B.
, с планировщиком D и коалиции B.
Пусть также ? (,B,D)... ?n(
Кроме того, пусть f:An - > A для некоторой области A и пусть ? - протокол для n процессоров. Будем говорить, что ? безопасно t-вычисляет функцию f в асинхронной модели для каждого частного планировщика PD и каждой коалиции B с не более, чем из t нечестных процессоров, если выполняются следующие условия.
Условие завершения (условие полноты). По всем входам все честные процессоры завершают протокол с вероятностью 1.
Условие безопасности. Существует ТР-противник A такой, что для каждого входа ,A) и ?(
Конфиденциальное вычисление функции
Общие положения. Для некоторых задач, решаемых в рамках методо-логии конфиденциальных вычислений, достаточно введения определения конфиденциального вычисления функции .
Пусть в сети N, состоящей из n процессоров P1,P2,...,Pn со своими секретными входами x1,x2,...,xn, необходимо корректно (т.е. даже при наличии t сбоящих процессоров) вычислить значение функции (y1,y2,...,yn)=f(x1,x2,...,xn) без разглашения информации о секретных аргументах функции, кроме той, информации, которая содержится в вычисленном значении функции.
По аналогии с идеальным и реальным сценариями, приведенными выше, можно ввести понятия "реальное и идеальное вычисление функции f" .
Пусть множество входов и выходов обозначается как X и Y соответственно, размерности этих множеств |X| =X и |Y| = ? . Множество случайных параметров, используемых всеми процессорами сети, обозначается через R, размерность - |R| = v. Кроме того, через W обозначим рабочее пространство параметров сети. Через T(r) обозначается трафик в r-раунде, через ti(r) - трафик для процессора i в r-том раунде, r0 и rk - инициализирующий и последний раунды протокола соответственно и r* - заданный неким произ-вольным образом раунд выполнения протокола P.
Пусть функцию f можно представить как композицию d функций (функций от двух аргументов-векторов) 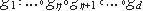
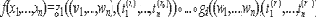
Аргументы функции g? являются рабочими параметрами w1,...,wn уча-стников протокола с трафиком (t1,...,tn) в r раунде.
Значения данной функции g? являются аргументами (рабочими параметрами протокола с трафи-ком (t1,...,tn) в r+1 раунде) для функции g?+1.
Из определения следует, что функция f:(Xn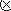 W)- > Y, где
W)- > Y, где
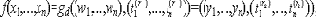
Введем понятие моделирующего устройства M. Здесь можно проследить некоторые аналогии с моделирующей машиной в интерактивных сис-темах доказательств с нулевым разглашением (см., например, [,]).
Пусть р?Прот - распределение вероятностей над множеством историй (трафика Т и случайных параметров) нечестных участников во время выполнения протокола Р.
Моделирующее устройство, взаимодействующее с нечестными участниками, осуществляет свое функционирование в рамках идеального сценария. Моделирующее устройство М создает распределение вероятностей параметров взаимодействия и?Прот между М и нечестными участниками.
Протокол P конфиденциально вычисляет функцию f(x), если выпол-няются следующие условия:
align="justify"Условие корректности. Для всех несбоящих процессоров Pi функция
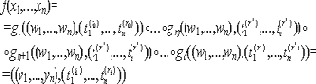
вычисляется с вероятностью ошибки близкой к 0.
Условие конфиденциальности. Для заданной тройки (x,r,w) Rnр?Прот и и?Прот являются статистически не различимыми.
Функция f, удовлетворяющая условиям предыдущего определения называется конфиденциально вычислимой.
Проверяемые схемы разделения секрета как конфиденциальное вычисление функции
Для вышеприведенной проверяемой схемы ПРС и обобщенных моделей противника, сбоев, взаимодействия и вычислений синтезируем схему разделения секрета, которая являлась бы работоспособной в протоколах конфиденциальных вычислений. Рассматривается полностью синхронная сеть взаимодействующих процессоров в условиях проявления By-сбоев. Противник представляется как активный динамический t-противник. Взаимодействие процессоров может осуществляться посредством конфиденциальных каналов связи. Кроме того, существует широковещательный канал связи.
Схема проверяемого разделения секрета, рассматриваемая как схема конфиденциального вычисления функции, значение которой является распределенный среди процессоров проверенный на корректность и затем восстанавливаемый секрет, обозначается как ПРСК.
Пусть сеть N состоит из n процессоров P1,P2,...,Pn-1,Pn, где Pn - дилер Д сети N. Множество секретов обозначается через S, размерность этого мно-жества |S| =l. Множество случайных параметров, используемых всеми процессорами сети, обозначается через R, размерность |R| = v. Через W обозначается рабочее пространство параметров сети.
Требуется вычислить посредством выполнения протокола P=(РзПр,ВсПр) функцию f(x), где f - представляется в виде композиции двух функций g o h. Пусть функция g:(SnW) - > W, а функция h:W - > S.
Проверяемая схема разделения секрета ПРСК называется t-устойчивой, если протокол разделения секрета и проверки правильности разделения РзПр и протокол восстановления секрета ВсПр являются t-устойчивыми. Функция f является конфиденциально вычислимой, если конфиденциально вычислимы функции g и h.
t-Устойчивая верифицируемая схема разделения секрета ПРСК - есть пара протоколов РзПр и ВсПр, при реализации которых выполняются следующие условия.
Условие полноты. Пусть событие A1 заключается в выполнении тождества
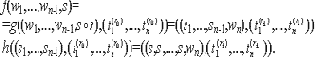
Тогда для любой константы c>0 и для достаточно больших n вероятность Prob(A1)>1-n-c.
Условие корректности. Пусть событие A2 заключается в выполнении тождества
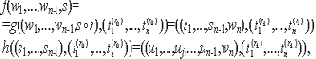
где uj=s для j
Тогда для любой константы c>0, достаточно больших n, для границы t*< t и любого алгоритма Прот вероятность Prob(A2)-c.
Условие конфиденциальности.
Функция 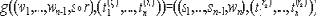
конфиденциально вычислима.
Функция 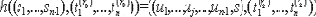
Свойство полноты означает, что если все участники протоколов РзПр и ВсПр следуют предопределенным вычислениям, тогда любая коалиция несбоящих процессоров может восстановить секрет s. Свойство корректности означает, что при действиях t-противника Прот, любая разрешенная коалиция из n процессоров сети может корректно разделить, проверить и восстановить секрет. Свойство конфиденциальности вытекает из свойства конфиденциальности функции.
Схема ПРСК
Предлагаемая схема ПРСК, является (n/3-1)-устойчивой и использует схему разделения секрета Шамира.
Пусть n=3t+4 и все вычисления выполняются по модулю большого простого числа p>n. Из теории кодов с исправлением ошибок известно, что если вычисляем полином f степени t+1 в n-1различных точках i, где i=1,...,n-1, тогда по данной последовательности si=f(i), можно восстановить коэффициенты полинома за время, ограниченное некоторым полиномом, даже если t элементов в последовательности произвольно изменены. Это вариант кода Рида-Соломона, известный как код Берлекампа-Велча. Пусть далее K - параметр безопасности и K/n означает [K/n] .
Протокол РзПр
Протокол ВсПр
?l,(i-1)K/n+m для l=1,...,n и m=K/n.
?l,(i-1)K/n+m для l=1,...,n и m=1,...,K/n.
Заметим, что если дилер Д честен, в конце протокола ВсПр противник, даже зная секрет s и t долей "подкупленных" процессоров, ничего не узнает о долях секрета честных процессоров, так как полином имеет степень t+1 и ему необходимо для интерполяции t +2 точки.
Доказательство безопасности схемы проверяемого разделения секрета
Теорема 2.3. Схема ПРСК является (n/3-1)-устойчивой.
Доказательство. Пусть
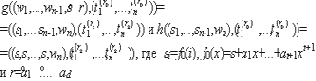
(то есть полином, созданный, с использованием случайного параметра r дилера Д).
При рассмотрении протокола РзПр напомним, что ti - трафик процессора Pi. Ясно, что для всех процессоров Pi, iД, Д=Pn+1, функция входа немного сложнее. Пусть mi - сообщение, который дилер распространяет процессору Pi в 5-м раунде, если Pi сообщил об ошибке в 4-м раунде или сообщение, которое дилер послал процессору Pi в 1-м раунде, если Pi не заявлял об ошибке. Тогда ID(tD)=f(0), где f=BW(m1,...,mn) - полином степени t+1, следующий из интерполяции Берлекампа-Велча. Функция выхода более простая: Oi(ti)=mi, где mD=?.
При рассмотрении протокола ВсПр, определим вход и выход функции g. Функция входа Ii для процессора Pi определена как следующая: пусть mi,j - сообщение, посланное процессором Pi процессору Pj в 1-м раунде; Ii(ti)=hi(0), где hi=BW(mi,1,...,mi,n) - многочлен степени t+1, следующий из интерполяции Берлекампа-Велча. Если такого полинома не существует, то Ii(ti)=0. Функция выхода следующая: пусть Mi - сообщение, распространяемая процессором Pi в раунде 9; Oi(ti)=F(0)=s, где F=BW(M1,...,Mn) - полином степени t+1, следующий из интерполяции Берлекампа-Велча.
Далее для доказательства теоремы необходимо доказать выполнения условий полноты, корректности и конфиденциальности. Полнота. Если дилер Д - честный, исходя из свойств схемы ПРСК, любой несбоящий процессор может восстановить секрет s с вероятностью 1, так как посредством определенных выше функций g и h
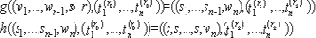
реализуется

Корректность. Для доказательства теоремы необходимо доказать следующие две леммы.
Лемма 2.3. Пусть функция g имеет вид
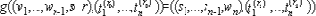
Тогда g корректно вычисляет доли секрета s1,...,sn-1.
Доказательство. Сначала мы должны доказать, что для всех несбоящих процессоров Pi, значение Ii(ti) равно корректному входу.
Если дилер Д - честный, то mi=f(i), где f - многочлен степени t+1 со свободным членом s (секретом). Таким образом, ID(tD)=s - если дилер честный. Второе условие корректности состоит в том, что с высокой вероятностью должно выполняться O(t)=g(I(t)). В нашем случае это означает, что с высокой вероятностью значения mi, находящиеся у несбоящих процессоров, должны предназначаться для единственного полинома степени t+1. Это справедливо с вероятностью 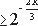
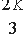 битов выбраны действительно случайно несбоящими процессорами в раундах 2 и 6. Каждый бит представляет запрос, на который нечестный дилер, распределивший "плохие" доли, должен будет ответить правильно в следующем раунде только с вероятностью 1/2 (то есть, если он предскажет правильно значение бита). Следовательно, это и есть граница для вероятности ошибки
битов выбраны действительно случайно несбоящими процессорами в раундах 2 и 6. Каждый бит представляет запрос, на который нечестный дилер, распределивший "плохие" доли, должен будет ответить правильно в следующем раунде только с вероятностью 1/2 (то есть, если он предскажет правильно значение бита). Следовательно, это и есть граница для вероятности ошибки
Лемма 2.4. Пусть функция h имеет вид
Тогда h корректно восстанавливает секрет s.
Доказательство. Понятно, что для всех несбоящих процессоров Ii(ti)=si - корректная доля входа. В этом случае необходимо проверить, что с высокой вероятностью O(t)=h(I,t), а это означает, что необходимо доказать, что
Это равенство не выполняется, если:
-
любой сбоящий процессор Pl "преуспевает" в получении случайного "мусора" вместо значений pl(j) в раунде 2 (в этом случае, сообщения Mi не будут интерполировать полином);
процессор Pi распределяет pl(j) в раунде 2 и использует полином со свободным членом, отличным от нуля (в этом случае, Mi восстановит другой секрет).
Так как мы уже знаем, что Pl "преуспевает" в любом из двух описанных случаев с вероятностью 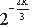 ), что для достаточного большого K, является экспоненциально малым.
), что для достаточного большого K, является экспоненциально малым.
Конфиденциальность. Для доказательства теоремы необходимо доказать следующие две леммы.
Лемма 2.5. Пусть функция g имеет вид
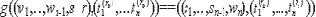
Тогда g конфиденциально вычислима в отношение долей секрета s1,...,sn-1.
Доказательство. Доказательство условия конфиденциальности для функции g заключается в описании работы моделирующего устройства М, которое взаимодействует со сбоящими процессорами (в том числе с нечестным дилером) и создает "почти" такое же распределение вероятностей, которое возникает у сбоящих процессоров во время реального выполнения протокола РзПр.
Необходимо рассмотреть два случая.
Случай A: Дилер нечестен до начала 1-ого раунда. Моделирующее устройство будет следовать только командам процессоров с единственным исключением, что оно будет "передавать" их в какое-либо время противнику в случае "сговора". Так как процессоры не сотрудничают по любому входу, то это сводит моделирование к работе схемы проверяемого разделения секрета с нечестным дилером. Так что моделирование будет неразличимо с точки зрения противника.
Случай B: Дилер честен до начала 1-ого раунда. Моделирующее устройство в 1-м раунде будет создавать случайный "ложный" секрет s' и распределять его процессорам в соответствии с командами протокола с полиномом f'. Если дилер честен в течение всего протокола, тогда он будет выполняться с точки зрения противника как обычный протокол проверяемого разделения секрета с честным дилером. Если дилер нечестен после 1-ого раунда противник и моделирующее устройство получит из оракула истинный вход s дилера. В этом случае моделирующее устройство передает управление от дилера к противнику и меняет полином, используемый для разделения на новый многочлен f" такой, что f"(0)=s и f"(i)=f'(i) для всех процессоров Pi, которые были "подкуплены" противником. Изменения моделирующего устройства в соответствии со случайным полиномом fi, используемым для доказательств с нулевым разглашением (см, например, [,,]) делает их совместимыми с любым широковещательным каналом. Моделирующее устройство может всегда сделать это, так как противник имеет не более t точек полинома степени t+1. Далее моделирующее устройство использует полином f" для работы несбоящих процессоров, все еще находящихся под его управлением.
Можно утверждать, что для противника эти вычисления не отличимы от реальных вычислений. Единственный момент, отличающийся от реальных вычислений, - это тот факт, что доли секрета, которые противник получает до того, как дилер становится нечестным, созданы с использованием другого полинома. Но благодаря свойствам полиномов - это не является проблемой для моделирующего устройства, в том случае, если дилер нечестен.
Лемма 2.6. Пусть функция h имеет вид
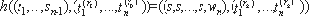
Тогда h конфиденциально вычислима в отношение секрета s.
Доказательство. Работа моделирующего устройства M сводится к следующему.
Описание работы моделирующего устройства M
1. В раунде 1 M моделирует процессор Pi, выбирая случайный полином h'i степени t+1 и посылает h'i(j) к Pj. В этом месте моделирующему устройству позволено получить из оракула выход функции, так что M будет изучать истинный секрет s. Если такой процессор является "подкупленным" противником Прот в конце этого раунда (или в следующих раундах), то и M, и Прот узнают истинную долю sl и M должен изменить полином h'l в соответствии с тем, что h'l(0)=sl, но без изменения значения в точках, уже известных противнику. Моделирующее устройство M может всегда cделать это, потому что противник имеет не более t точек полинома степени t+1.
2-8. В течение раундов 2-8 моделирующее устройство полностью следует явно командам процессоров. Так как все что делают процессоры в этих раундах полностью случайно и нет влияния на их входы, M будет всегда способен создать неразличимые распределения.
9. Моделирующее устройство M выбирает полином g степени t+1 такой, что g(0)=s и затем для каждого процессора Pi, устройство M распространяет g(i)+pi(i)+...+pn(i), где pj - полином, распределенный процессором Pj в течение раундов 2-8 моделирования. Интерполяция Рида-Соломона этих значений даст как результат секрет s. Если процессор Pl является сбоящим в конце этого раунда, тогда и M, и Прот узнают из оракула истинную долю входа sl. Если slM только изменит значение pl в точке l так, чтобы сделать полную сумму соответствующей такой широковещательной передаче.
Моделирование неотличимо от реального выполнения с точки зрения противника. Фактически, в раундах 2-8 все сообщения случайны и не связаны с входом, так что моделирующее устройство может легко играть роль несбоящих процессоров. В раунде 1 противник просматривает не более t долей реального входа несбоящих процессоров. В соответствии со свойствами схемы разделения секрета Шамира, эти доли полностью случайны и, таким образом, могут моделироваться даже без знания реального входа (как и в случае с моделирующим устройством). В раунде 9 реальная доля распространена "скрытым образом" как случайный "мусор", а это позволит моделирующему устройству распространять сообщение несбоящих процессоров с необходимым распределением даже без знания реального входа.
С доказательством лемм 2.2 - 2.5 доказательство теоремы 2.3 следует считать законченным.
Здесь уместно сделать следующее замечание. Схемы (протоколы) конфиденциальных вычислений являются чрезвычайно сложным объектом исследований. Как видно из сказанного выше, даже описание и доказательство безопасности одного из базовых примитивов в протоколах конфиденциального вычисления функции, - схемы проверяемого разделения секрета являются чрезвычайно громоздкими и сложными. Демонстрация собственно протоколов конфиденциальных вычислений, решающих те или иные теоретические или прикладные задачи, выходит за рамки настоящей работы.
RL-прототип модели синхронных конфиденциальных вычислений
Зададимся вопросом "Существует ли реальный вычислительный аналог представленной модели синхронных конфиденциальных вычислений ?". Такой вопрос важен и с прикладной, и с содержательной точки зрения. Рассмотрим многопроцессорную суперЭВМ семейства S-1 на базе сверхбыстродействующих процессоров MARK IIA (MARK V). Такую вычислительную систему назовем RL-прототипом (real-life) модели синхронных конфиденциальных вычислений в реальном сценарии.
Проект семейства систем высокой производительности для военных и научных применений (семейства S-1) является в США частью общей программы развития передовых направлений в области числовой обработки информации.
Исходя из целей программы, можно сделать вывод о возможности применения указанной вычислительной системы в автоматизированных системах критических приложений. Поэтому требования высокой надежности и безопасности программного обеспечения систем являются обязательными.
В указанной многопроцессорной системе используются специально разработанные однопроцессорные машины, образующие семейство, то есть имеющие однотипную архитектуру. В систему может входить до 16 однопроцессорных ЭВМ, сравнимых по производительности с наиболее мощными из существующих суперЭВМ. В дополнение к обычному универсальному оборудованию процессоры семейства S-1 оснащены специализированными устройствами, позволяющими выполнять высокоскоростные вычисления в тех прикладных областях, где планируется использование данной многопроцессорной системы. К таким операциям относятся вычисления функций синуса, косинуса, возведения в степень, логарифмирования, операции быстрого преобразования Фурье и фильтрации, операции умножения над матрицами и транспонирования.
Системы семейства S-1 предоставляют в распоряжение пользователя большую сегментированную память с виртуальной адресацией в несколько миллиардов 9-разрядных байтов. Процессоры соединены между собой с помощью матричного переключателя, который обеспечивает прямую связь каждого процессора с каждым блоком памяти (см. рис.2.10). При обращениях к той или иной ячейке памяти процессоры всегда получают последнее записанное в ней значение. Команды выполняются в последовательности: "чтение - операция - запись". С целью повышения быстродействия памяти в составе каждого процессора имеются две кэш-памяти: первая - объемом 64 Кбайт для хранения данных, вторая - объемом 16 Кбайт (с перспективой наращивания). В обоих типах кэш-памяти длина набора составляет 4, а длина строки 64 байта.
В операционной системе Amber, предназначенной для вычислительных систем семейства S-1, предусмотрена программа планировщик, который на нижнем уровне архитектуры системы обеспечивает эффективный механизм оперативного планирования заданий на одном процессоре.
Основным правилом планирования здесь является назначения в порядке очереди. На уровне такого одноприоритетного планирования каждое задание выполняется до тех пор, пока не возникает необходимость ожидания какого-либо внешнего события или не истечет выделенный квант процессорного времени. Планировщик высокого уровня осуществляет более сложное планирование, в основу которого положена некоторая общая стратегия. Результатом его работы являются соответствующим образом измененные параметры планировщика нижнего уровня: приоритеты заданий или размеры квантов времени.
Одной из важнейших особенностей многопроцессорной системы семейства S-1 является наличие общей памяти большой емкости, позволяющей осуществлять широкомасштабный обмен данными между заданиями. Если два задания работают с одним и тем же сегментом памяти, они пользуются его единственной физической копией, в то время как другие области пространства адресов остаются в их собственном владении. Таким образом, задания оказываются защищенными от неосторожных попыток изменить их внутренне состояние. Между двумя заданиями можно установить жесткий режим чтения-записи, когда одному заданию разрешаются операции чтения-записи, а другому только операции чтения из данного сегмента.
Операционная система Amber имеет большие возможности для реконфигурации системы в случае возникновения сбоев (внештатных ситуаций). Если требуется вывести из конфигурации процессор, выполнение на нем приостанавливается и производится их перераспределение на другие процессоры. Когда процессор или память вводятся в рабочую конфигурацию, они становятся обычными ресурсами системы и загружаются по мере необходимости.
Таким образом, можно проследить широкий круг аналогий между моделью конфиденциальных вычислений и ее вычислительным прототипом. В этом случае центральный коммутатор совместно с устройствами памяти можно рассматривать и как широковещательный канал, и как набор конфиденциальных каналов связи между процессорами. Конфиденциальность каналов может рассматриваться в том случае, если существует возможность предотвратить несанкционированный доступ к блокам памяти или хранить и передавать данные в зашифрованном виде.
Привязка во времени многопроцессорной системы S-1 осуществляется посредством устройства синхронизации. Параметром безопасности системы может являться длина строки (64-256 Кбайт). Вычислительная система типа S-1 позволяет осуществлять разработку прототипов распределенных вычислительных систем и исследование характеристик многосторонних протоколов различного типа, как криптографического характера, так и нет. К такой разновидности распределенных вычислений можно отнести следующие протоколы, имеющие, в том числе, и прикладное значение.
- обеспечения правильности подачи и подсчета голосов;
- обеспечения тайного голосования избирателей;
- обеспечения невозможности срыва выборов или искажения их результатов.
- Протоколы выработки общей случайной строки. Протокол позволяет безопасным образом группе участников, часть из которых являются нечестными, выработать с равномерным распределением вероятностей общую для всех случайную строку. Такой протокол является часто используемым вычислительным примитивом для построения более сложных протоколов распределенных вычислений.
Методы конфиденциальных вычислений могут позволить для многопроцессорных систем проектировать высокозащищенную программно-аппаратную среду для использования в автоматизированных системах критически уязвимых объектов информатизации.
Содержание раздела
